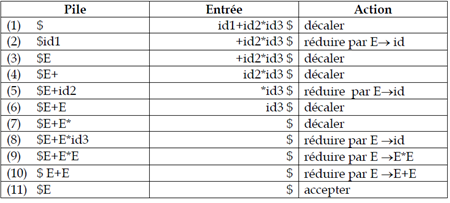
Une Définition Dirigée par la Syntaxe (DDS) est un formalisme permettant d’associer
des actions à une règle de production de la grammaire. On appelle ainsi DDS la donnée d’une
grammaire et des règles sémantiques. On parle de grammaire attribuée.
Dans une DDS, on a les éléments
suivants :
- Chaque symbole de la
grammaire (VT ou VN) possède un ensemble
d’attributs (variables) pouvant être synthétisés ou hérités
de ce
symbole. Si un nœud d’arbre syntaxique (étiqueté par un symbole) est représenté par un
enregistrement, un attribut correspond à un nom de champ de cet enregistrement.
- Chaque règle de
production de la grammaire possède un ensemble de règles sémantiques qui permettent de calculer la valeur des
attributs associés au symbole apparaissant dans la production
- Une règle sémantique
est une suite d’instructions algorithmiques (elle peut contenir des affectations, des instructions d’affichage,
des instruction de contrôle, etc.)
Les règles sémantiques impliquent des
dépendances entre les attributs. Ces dernières sont représentées par un graphe de dépendance
(GD) à partir duquel en déduit un ordre d’évaluation des règles sémantiques.
Remarque
Un arbre syntaxique muni des valeurs d’attributs
à chaque nœud est appelé arbre décoré (ou annoté). Le processus de calcul
des valeurs des attributs aux nœuds est appelé décoration (ou annotation) de l’arbre.
7.1 Grammaires attribuées
7.1.1 Attributs synthétisés
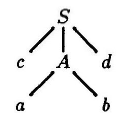
Un attribut synthétisé d'un nœud est calculé à partir des attributs au niveau des fils de ce nœud dans l’arbre syntaxique. Les attributs synthétisés sont très
utilisés en pratique. Une DDS qui utilise uniquement les attributs synthétisés est appelée Définition S-attribuée.
Un arbre syntaxique pour une définition
S-attribuée est toujours décoré en évaluant les règles sémantiques pour les attributs de chaque nœud du
bas vers le haut (peut être adapté à une analyse ascendante : grammaire LR, par exemple).
Exemple
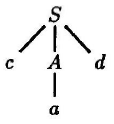
7.1.2 Attributs hérités
Un attribut hérité est un attribut dont
la valeur, à un nœud d’un arbre syntaxique, est définie en fonction du père et/ou des frères de ce nœud. Il
est souvent plus naturel d’utiliser des attributs hérités qui sont bien adaptés à l’expression des dépendances
contextuelles.
Exemple
7.1.3 Structure d’une DDS
Dans une DDS, chaque production de la
grammaire (A → a) possède un ensemble de règles sémantiques de
la forme :
b := f(C1, C2, …, Ck)
f : est une fonction, souvent écrite
sous forme d’expressions et parfois sous forme d’un appel de procédure.
b : est soit un attribut synthétisé de
A, soit un attribut hérité d’un symbole en partie droite de la règle.
C1, C2, …, Ck : sont
des attributs de symboles quelconques dans la règle de production.
7.2 Schéma de traduction
Un schéma de traduction est comme une grammaire attribuée mais
précise quand on fait les actions pendant un
parcours de l'arbre en profondeur, elles sont insérées dans les
membres droits des règles.
- Si une action calcule un attribut d'un non-terminal du
membre droit, elle doit être placée
avant lui
- Si une action utilise un attribut d'un non-terminal du
membre droit, elle doit être placée
après lui
Exemple : traduction postfixe des
expressions additives
E
--> T R
R
--> addop T
{ print(addop.lexeme) } R | e
T
--> num { print(num.val) }
7.2.1. Traduction descendante
Pour l'analyse descendante, on
élimine la récursivité à gauche dans la grammaire. Il faut aussi adapter les attributs
Exemple
E --> E + T E.val := E1.val + T.val
E --> E - T E.val := E1.val - T.val
E --> T E.val
:= T.val
T --> ( E
) T.val
:= E.val
T -->
chiffre E.val
:= chiffre.val
Élimination de la récursivité à gauche
E --> T { E'.he
:= T.val } E' {E.val
:= E'.sy }
E' --> + T {
E'1.he := E'.he + T.val } E' {E'.sy
:= E'1.sy }
E' --> -
T
{ E'1.he := E'.he - T.val } E' {E'.sy
:= E'1.sy }
E' --> e {E'.sy := E'.he }
T --> ( E
) {T.val
:= E.val }
T --> N {T.val
:= N.val }
L'attribut E'.he sert à transmettre la valeur de
l'expression située à gauche
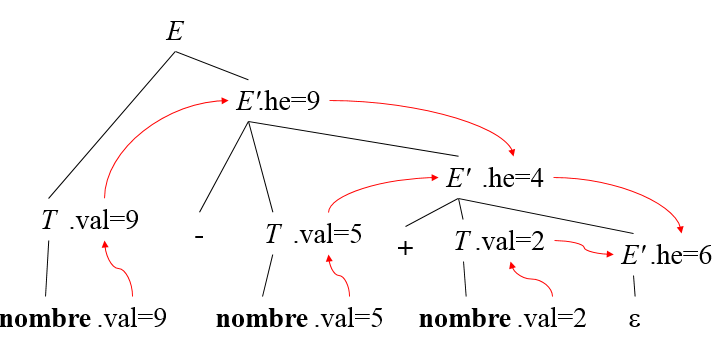
7.2.2 Traduction descendante
Donnée
: un
schéma de traduction non récursif à gauche
Résultat
: le
code d'un traducteur descendant
Pour chaque non-terminal A, construire une fonction dont les
paramètres sont les attributs hérités de A
et qui renvoie comme valeur les attributs synthétisés de A (on suppose qu'il n'y en a qu'un). Le code pour A décide quelle règle appliquer en
fonction du symbole courant dans la donnée. Pour chaque attribut d'une variable
du membre droit, déclarer une variable locale.
Le code associé à une règle
parcourt le membre droit et fait les actions suivantes :
- Pour un symbole terminal X avec un attribut x, sauvegarder la
valeur de x dans une variable locale et lire X.
- Pour un non-terminal B, faire c := B(b1, b2, ... bk)
où c est l'attribut synthétisé de B et b1, b2, ... bk
sont les attributs hérités de B.
- Pour une action, faire l'action.
Le problème est de calculer les
attributs hérités, on effectue les actions seulement
au moment où on réduit.
Dans une règle A --> X1
X2 ...Xn, au moment où on passe Xi,
on a dans la pile X1
X2 ...Xi-1 mais pas A.
- Si un attribut hérité de Xi
dépend d'un attribut de A, quand et comment le calculer ? on
ira le chercher dans la pile et non dans la règle. La méthode présentée est applicable
à certaines grammaires L-attribuées dont la grammaire sous-jacente est LR(1).